BLOG


Gute Nachrichten: Sie haben beschlossen, die Messung der Last-Click Attribution aufzugeben und sich für dieses Jahr fest vorgenommen, Ihre Analyse der Mediaattribution zu verbessern. War der Verlust der Cookies von Drittanbietern und Ihrer Fähigkeit, die Leistung der Kanäle zu messen, der Grund dafür?
Oder Sie sind der Meinung, dass es an der Zeit ist, die Art und Weise zu verändern, wie Sie Medien am Upper-Funnel bewerten, dann kann die Modellierung des Mediamixes eine Lösung sein. Doch weshalb? Der Hauptgrund liegt darin, dass damit Berichte über die Leistung erstellt werden können, ohne dass an das Impressions- und Klick-basierte Journey-Tracking dieselben Anforderungen gestellt werden.
Es handelt sich um eine 50 Jahre alte Praxis, die auf den beiden folgenden Grundsätzen beruht:
Kurz gesagt, die Modellierung des Mediamixes konzentriert sich auf das Verständnis der relativen Beiträge der verschiedenen Kanäle oder der verschiedenen Aktivitätsstufen des Funnels zur Performance einer Medienkampagne.
Die Modellierung des Mediamixes kann Aufschluss über Basis- und Zusatzkonversionen und -einnahmen geben. Einfach ausgedrückt sind inkrementelle Ergebnisse der prozentuale Anteil der medienwirksamen Conversions, die ohne Marketingaktivitäten nicht stattgefunden hätten. Die Analyse von Basis- und inkrementellen Ergebnissen kann die zugrundeliegende Markenbekanntheit und -loyalität auf lange Sicht sowie die Auswirkungen kurzfristigerer Werbeaktivitäten und Wettbewerbsniveaus aufzeigen.
Traditionell wurden für diese Berechnungen bewährte statistische Verfahren wie die lineare Regressionsanalyse verwendet, aber es werden immer ausgefeiltere Tools entwickelt, um die Modellierung des Mediamixes auf das nächste Level zu bringen.
Seit den 1960er Jahren haben Statistiker geduldig Analysen zur Modellierung des Mediamixes mit Hilfe traditioneller ökonometrischer Instrumente wie der linearen Regression durchgeführt, manchmal sogar von Hand. Aber die Daten aus Mediaaktivitäten sind im Laufe der Jahre immer komplexer geworden, und die Unzulänglichkeiten der traditionellen Methoden wurden immer deutlicher. Ebenso sind diese Daten zunehmend verfügbar und granularer geworden, wobei die Daten von Erstanbietern durch Daten von Zweit- und Drittanbietern angereichert wurden. Zu guter Letzt hat sich die Rechenleistung von Computern so stark vervielfacht, sodass alle Voraussetzungen für die Anwendung neuer Methoden des Machine Learnings im Rahmen der Analyse von Mediamixmodellen sind erfüllt.
Einige dieser Ansätze, wie Robyn, das Machine-Learning-gestützte und halbautomatische Open-Source-Paket von Meta zur Modellierung des Marketing-Mixes, welches 2021 auf den Markt kam, versuchen, die Herangehensweise zu vereinfachen, indem sie es Nutzern ermöglichen, ihre Kosten- und Konversionsdaten in einen Data-Science-Workflow zu “gießen” und eine Auswahl von Modellen zu generieren. Kurz gesagt, das maschinelle Lernen vereinfacht den Prozess: Es ist in der Lage, das Modell iterativ und schnell für eine bessere Performance zu optimieren.
Haben Sie erwartet, dass ein einfach zu verwendendes (oder auch nicht so einfach zu verwendendes) Tool die Arbeit für Sie perfekt erledigen würde?
Auch wenn es technisch möglich ist, die Daten einfach in die Maschine zu geben und darauf zu hoffen, dass alles gut geht, sind wir davon überzeugt, wie wichtig der strategische Beitrag von Datenwissenschaftlern, Statistikern und Fachleuten ist, um ein wirklich relevantes und effizientes Modell zu entwickeln.
Hier sind einige Beispiele, in denen eine genauere Untersuchung mehr als willkommen wäre:
Lassen Sie uns diesen speziellen zuletzt aufgeführten Fall ein wenig näher betrachten. Nehmen wir an, Sie haben beschlossen, die “bezahlte Suche” als einen einzigen Kanal in Ihre Analyse aufzunehmen. Das scheint logisch zu sein, aber innerhalb jedes Kanals kann es unterschiedliche Verhaltensweisen der Daten geben, was dazu führt, dass diese unterschiedlichen Muster die Genauigkeit des Modells einschränken:

Durch die Untersuchung der Daten vor der Modellerstellung können diese Unterschiede ersichtlich gemacht werden, z. B. zwischen Kampagnen für Marken-Keywords und generischen Keywords oder Leistungsunterschiede zwischen den Regionen, was die Modellerstellung beeinflussen und die Modellgenauigkeit verbessern kann:
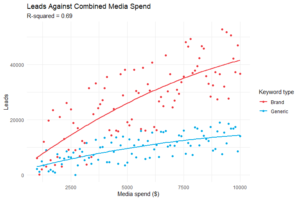
Die Kurzsichtigkeit, die durch verborgene Muster in den verketteten Daten verursacht wird, kann zu fragwürdigen Entscheidungen führen, die unnötige Risiken und potenziell katastrophale Folgen für die Rentabilität der Kampagne haben.
Abonnieren Sie unseren monatlichen Newsletter.
Zu den potenziellen negativen Auswirkungen eines übermäßigen Vertrauens in die Modellierung des Mediamixes durch maschinelles Lernen gehört zum Beispiel, dass Sie Ihre Budgets völlig unangemessen verteilen, in irrelevante Kanäle übermäßig investieren oder andere mit zu geringen finanziellen Mitteln ausstatten. Sie könnten auch mit einer falsch interpretierten Modellausgabe enden – das wäre der Fall, wenn Ihnen ein aggregiertes Modell für das ganze Jahr zur Verfügung gestellt wird, Sie aber in Wirklichkeit ein stark saisonabhängiges Geschäft haben.
Die Lösung? In aller erster Linie der gesunde Menschenverstand. Fragen Sie sich, ob das, was das Modell ihnen präsentiert, intuitiv Sinn macht, basierend auf Ihrem Wissen über die Branche, das Unternehmen, seine Produkte und bisherigen Erfolge.
Und die zweite Option, welche die erste ergänzt: Die Umsetzung eines robusten Test- und Experimentierprozesses, um sich selbst die Möglichkeit zu geben, alle Szenarien, auch die unerwarteten, in einem kontrollierten Umfeld zu untersuchen.
Ist Media Mix Modeling Version 2023 für jedes Unternehmen und jede Branche geeignet? Es ist auf alle Fälle für Sie geeignet, wenn folgende Voraussetzungen erfüllt sind:
Wir hoffen, dass dieser erste Exkurs in die faszinierende Welt der Datenmodellierung des Mediamixes Ihnen geholfen hat, sich selbst die richtigen Fragen zu stellen. Zögern Sie nicht, unsere Experten zu kontaktieren, um herauszufinden, ob diese Technik für Ihr Unternehmen eine gute Wahl ist.
Unleash the true value of your data with our center of excellence, Proove Intelligence.
Unleash the true value of your data with our center of excellence, Proove Intelligence.
Unleash the true value of your data with our center of excellence, Proove Intelligence.
Abonnieren Sie unseren monatlichen Newsletter.

